PARTNERING WITH SOME OF THE WORLD’S LARGEST ORGANIZATIONS TO TRANSFORM THEIR CLOUD DATA OPERATIONS










Simplify. Automate. Accelerate.
Lift and shift cloud migrations do not work for today’s enterprise. Petabytes of data and metadata and 10’s of 1000’s of workloads must be moved to the cloud – fast. Hand coding is time and labor intensive. Lift and shift also fails to deliver agility and scalability in the cloud.
There’s a better, faster way. Automation.
Infoworks is the only unified platform to automate data migration and data operations, end-to-end.
Infoworks software migrates data, metadata, and workloads to the cloud 3x faster and at 1/3 the cost, while simultaneously modernizing cloud data operations, enabling new AI, ML, and analytics use cases to be delivered 4x faster.
Let us help you unlock the value of your data.
WHY INFOWORKS
Unlock the value of your most strategic asset, your data.
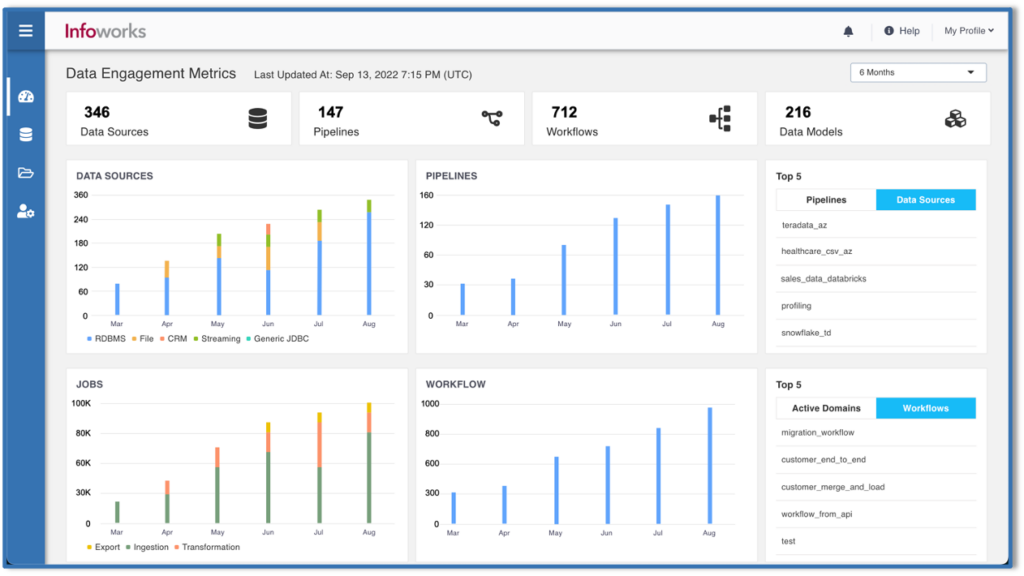
Infoworks software has proven to accelerate cloud migration and delivery of AI, ML, and analytics use cases. Simply install with your cloud platform to provide a complete foundation for your data. Power more analytics use cases faster and at a fraction of the cost of traditional approaches.
all with fewer specialized resources
The Infoworks Difference
Automation. Purpose-built for the cloud.
One Platform
Optimize performance, data lineage, metadata reporting, data governance, and security.
Automated
Automate data from end to end with fewer resources. No hand coding required.
Scalable
Power petabytes of data, and 10s of 1000s of AI, ML, and analytics use cases.
Simplified
Simplify configuration and operation through a single management console.
Portable
Work cross-platform with multi-cloud functionality. Any cloud, any data environment.
Ready to put automation to work?
Success Stories
Helping our clients make the most of their data.
Latest Resources
Explore what Infoworks solutions can do for you.

 Demo Videos
Demo Videos Infoworks software solutions enable enterprises to accelerate cloud migration and modernize cloud data operations for agility and scale. Learn more about migrating Hadoop to the cloud with Infoworks Replicator. Migrate EDW’s to the cloud and modernize cloud data operations with Infoworks Platform. Discover how Infoworks works – watch this short video. Explore our free tutorial […]

 White Papers
White Papers According to Harvard Business Review, 67% of enterprises are accelerating their migration to the cloud. Ensuring petabytes of data are rapidly, and accurately migrated to the cloud is a massive undertaking – one that’s proven unachievable with traditional solutions. Infoworks has pioneered a new approach to data validation. By integrating and automating the process end-to-end, […]

 Solution Briefs
Solution Briefs As enterprises migrate Hadoop to the cloud they’re faced with a unique set of challenges. Massive volumes of data need to be migrated with limited resources. Data must be continually synchronized to avoid business disruption. How can you ensure successful migration? Learn how Infoworks Replicator enables Hadoop migration to the cloud 3x faster and […]